General overview
- It probably is the most weird, tough year in our lives. This is the year that was stolen from us. The year when we were locked down. The year when you probably lost your job, your friend's parents had to close his business or that one when some of your friend hung on several months to get paid for an ERTE (Record of Temporary Employment Regulation). Or even worst, the year when you or some of your friends lost a loved one because of a fucking virus who no one had invited to the party.

Maybe we didn't deserve this year, or maybe yes, who knows. Chances are we deserve it somehow. Because of our unconcious way of living (not taking care about climate change, generating more and more polution and trash, we think we own Earth...) this virus has come to tell us "hey! stop going this way". You know, maybe nature is trying to say something to us.
I know a lot of people passed away since this pandemic started, loadsof them are facing real tought times like homeless, refugees, old and sick people... but c'mon many of us hasn't been bad at all. No travel, restricted social life, restricted movements between towns or provinces. Ok. But many of us have been lucky enough of having food, water, a roof above us, our family close by... I am grateful that my family is safe and healthy.
You know, 2020 hasn't been a year for exploring out there but for travel inside. At least we have good news now in 2021, the first version of the vaccine is already here. We hope it works #fingerscrossed
Working
I've been tracking some personal metrics this year and one of them are related to work. Fortunately I kept my job in spite of the pandemic.
Also, Crononauta decided to change the workday's length so we can spend more time with family, or just relax, because of the pandemic. That was an amazing idea and I think now we've found a great balance between work and life.
I worked more than 1499 hours this year. I reached an average of 35491 keystrokes and 3369 clicks a day, and a personal record of 67605 keystrokes and 6919 clicks in only one day.
Learning
One of my main goals for 2020 was to push my English skills to the next level, specially in speaking.
I've been studying English in some different ways in 2020. I signed up for a local English Academy from February to June and also for 8Belts from May until now. I took some grammar lessons from grammar books, YouTube videos and sometimes I used Babbel too.
I think the method that is working the most for me is 8Belts. I have a commitment of studying 40 minutes a day and to achieve 2 steps (or peldaños as they call them) every day. The vocabulary and sentences you learn are very useful, and you have to go over your vocabulary every day to earn points to step up a new peldaño. That's very nice because repetition is one of the keys to efectively remember everything. With 8Belts I also put my speaking skills into practice talking to natives from different countries weekly. I really feel more fluent at speaking than before, so this is great :)
I'm not planning to go back to a local academy for now. They're very focused only in grammar and to train you to pass Cambridge's or any other exam. What I want is to really get better at English, not passing an exam. That's totally secondary for me.
I added up a total of 268 hours of learning English this year.
-
211h with 8Belts / 18h of speaking training
I'm a Belt 6 right now, which means I can master the language but I'll continue studying this 2021 to get better and reach the Belt 7 ( -
47h with the local English academy
-
7h 39 min with Babbel
-
6h 40 min with grammar books
-
2h 30 min with YouTube lessons
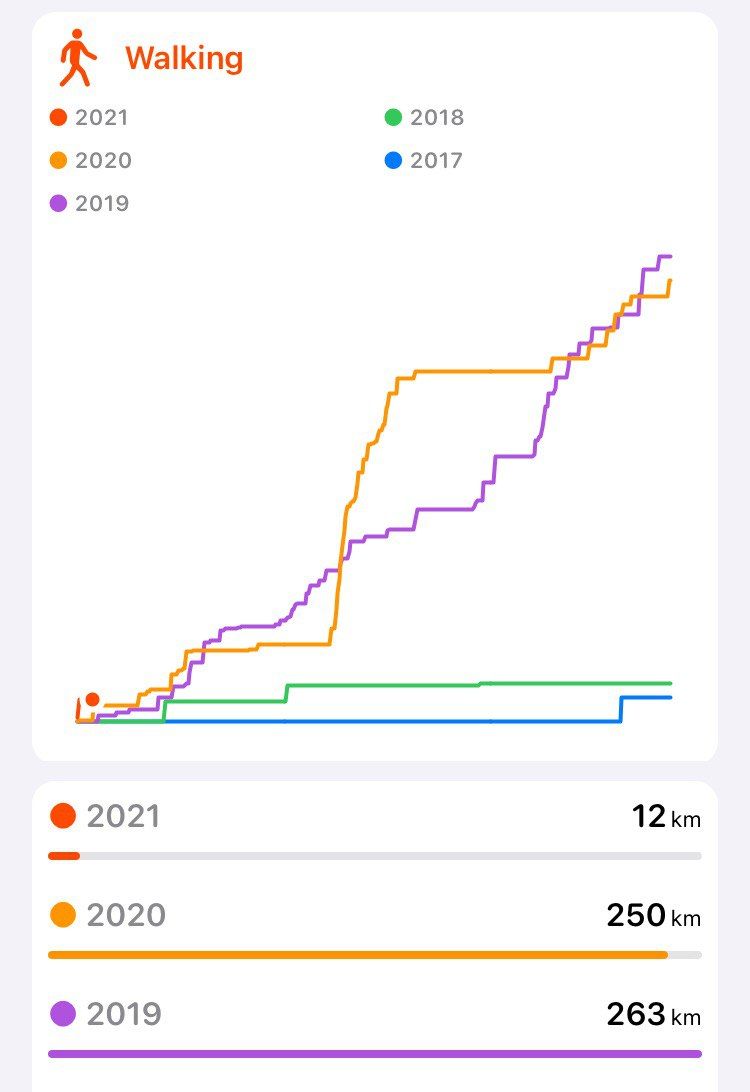
Fitness
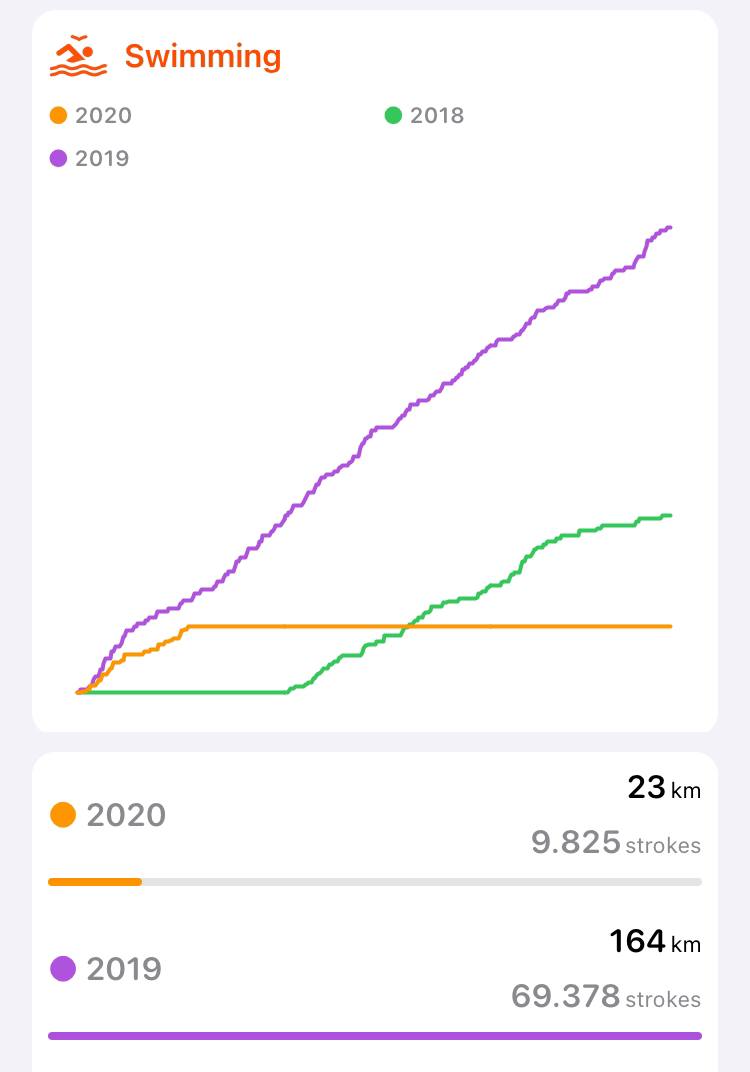
Another goal for this year was to keep swimming and try to beat my personal record of swum kms in 2019. That was not possible because of the pandemic.
I were doing bodyweight workouts at home during my lockdown, from March to June when I started going out of home to exercise, until I changed it for cycling. And I have to say that I had never done so many kms before :)
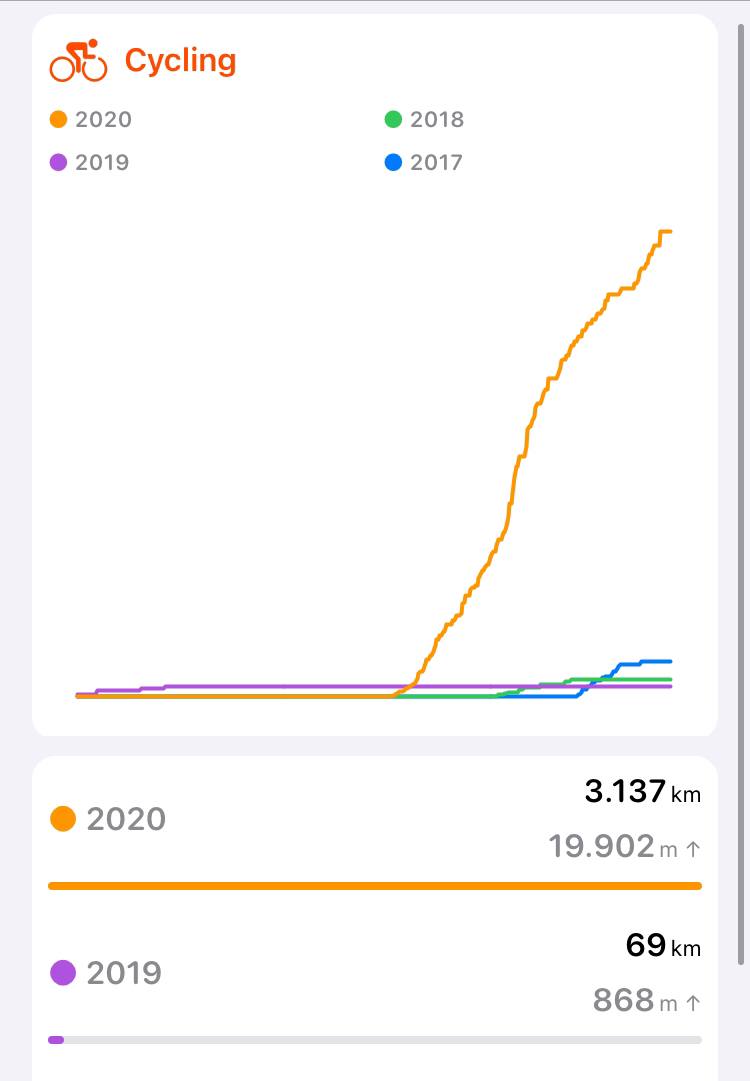
It's been great to "discover" cycling this year because I found a great balance among being outside, exercising, breathing fresh air, burning calories, sunbathing and, of course, staying safe because I've always been training alone.
I think cycling could be one of the safest sports you can practice during a pandemic, specially if you train alone like me, because you can go outside with no mask and without the risk to be infected or you infect other people. Just for the fact that you're completely alone in the middle of nature or a road.
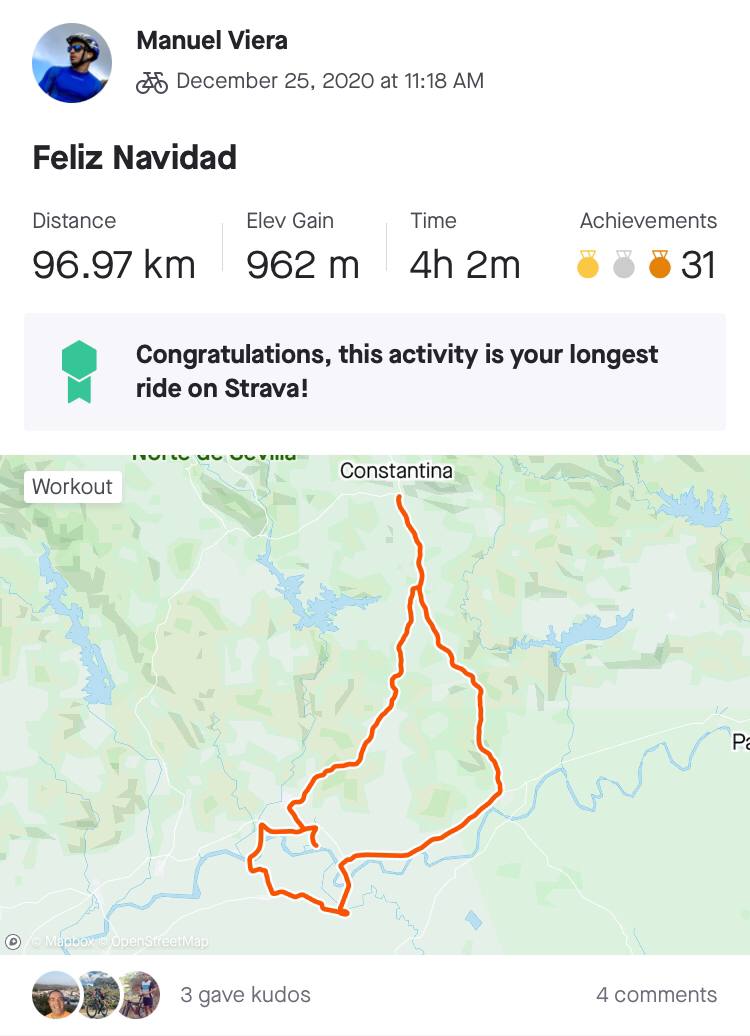
Even though I hadn't practiced cycling before, and taking int account that I started in June, I did a total of 3137kms and a 96.97 kms ride on 25th of December, which is my longest one. What a great gift!, don't you think? :)
But that's not all. I realized this year I burned more calories than in 2019! Wow!
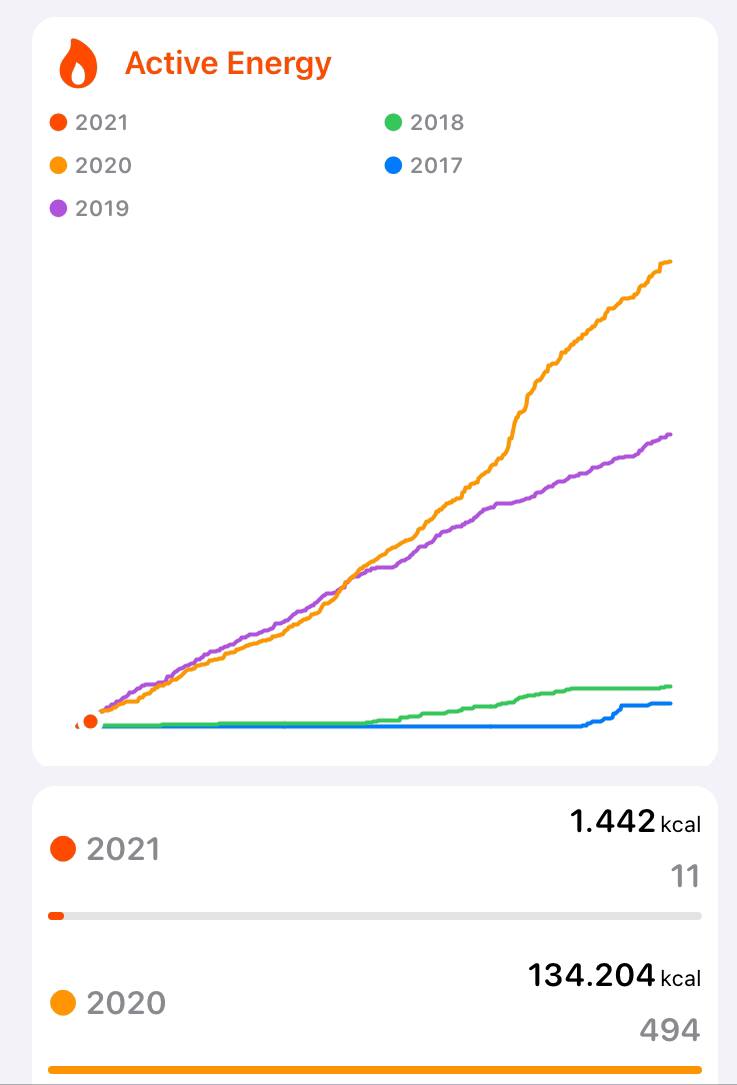
I couldn't ever imagined that I would be able to beat my 2019's total, so that had been great to find it out.
Relating to walking, my metrics are too low not only for 2020 but for 2019 as well. So, I'll need to get out of my chair more often :)
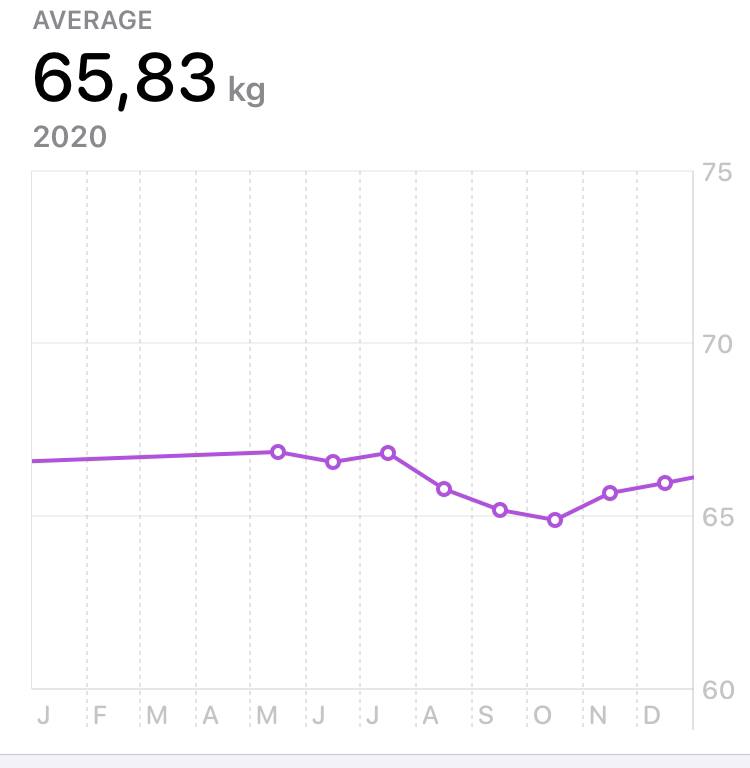
I started this self-tracking project in May, so I've been registering my weight daily since then and realized I've kept my weight in 2020. Keeping in mind that I'm around 170 cms tall, and we're facing movements restrictions, it's more than ok.
Another conclusion I can draw is that my diet is more than ok too. I've been following a mediterranean diet all my life and I've never needed to be on a diet. I always try to eat healthy as I can.
Reading
I think this 2020 has been the most productive year for me, because it has been the year the most focused I've been in my goals. And I'm proud of it.
Another goal for this 2020 was:
- Read at least 1 book a month ✓
Done. I read 20 books this year which is a total of more than 64h reading (I only have metrics from May until now).
Some of the books I have read are:
- Think Straight
- Do It Today
- When. The Scientific Secrets Of Perfect Timing
- El libro que tu cerebro no quiere que leas
- Infrastructure as Code
- Docker Deep Dive
- How To English: 31 Days to be an independent learner
- The Black Book of Speaking Fluent English
- Los 88 Peldaños del Éxito
Gaming
I've always played video games since I was a child / teenager but I left it back for a long time since I started to study and work. So, I wanted to recover that from the past and to start enjoying it again this year.
I played 24 games, which are more than 160 hours (cauz I only have metrics from May until now). I really enjoyed this time so I'll continue playing this 2021.
These are the games, in order of play, I played in 2020:
- [Jan] Horizon Zero Dawn
- [Jan] The Last Guardian
- [Feb] Hellblade Senua's Sacrifice
- [Feb] Journey
- [Feb] God of War
- [Mar] Uncharted 4
- [Apr] Call of Duty: Modern Warfare (Battle Royal)
- [May] Guacamelee!
- [May] Metal Slug 2
- [Jun] Metal Slug 3
- [Jun] The Last of Us: Remastered
- [Jun] The Last of Us: Left Behind
- [Jul] Control
- [Jul] Ghost of Tshushima
- [Aug] Ghost of Tshushima
- [Aug] Fall Guys
- [Aug] Cuphead
- [Sep] Cuphead
- [Sep] A Way Out
- [Oct] Rocket League
- [Nov] Overcooked 2
- [Oct] Overcooked 2
- [Oct] Rocket League
- [Dec] Worms Rumble
- [Dec] Cyberpunk 2077
- [Dec] Celeste
- [Dec] Rocket League
Media consumption
Even though I love making videos and photography, I haven't watched so many TV shows, series or movies this year.
My metrics says I watched 16 movies (31h) and 11 TV Shows / 78 episodes (121h). Mmm... ok.
Final thoughts
2020 has been a tough year for a lot of people, our movility has been reduced insanely but this is a great moment for instrospection, to know ourselves a little bit better, and for taking all this "free" time to learn something new and keep improving not only your skills but as human beings as well.
So, please, let's stay safe, be conscious and keeping physical distance :)
Thanks for reading.
]]>- Read 3 books and 8 articles.
- Watched 0 movies , 6 TV episodes and 1 talk .
- Listened to 0 podcasts episodes .
- Played 5 video games .
Books
]]>- Read 3 books and 8 articles.
- Watched 0 movies , 6 TV episodes and 1 talk .
- Listened to 0 podcasts episodes .
- Played 5 video games .
Books
How To English: 31 Days to be an independent learner
░░░▓▓▓▓▓▓▓▓▓▓▓▓
Los 88 Peldaños del Éxito
░░░░▓▓▓▓▓▓▓▓▓▓▓
3 pasos contra el sedentarismo
▓▓▓▓▓▓░░░░░░░░░
Recommended articles
How to renew Puppet CA and server certificates in place
Command Line Interface Guidelines
How to Write a Git Commit Message
Cron jobs on Amazon ECS
Disable PulseAudio Auto Volume
Minimal safe Bash script template
Recommended games
Celeste
Celeste is a platform game in which you controls a girl named Madeleine as she manage to get to the top of a mountain while avoiding so many deadly obstacles. Celeste was released in 2018 and was considered one of the best games of 2018. You'll love this game if you like 8-bit style and challenging games :)
- Read 3 books and 14 articles.
- Watched 2 movies , 6 TV episodes and 0 talks .
- Listened to 0 podcasts episodes .
- Played 2 video games .
Books
How To English: 31 Days to be an independent learner
░░░▓▓▓▓░░░░░░░░
- Read 3 books and 14 articles.
- Watched 2 movies , 6 TV episodes and 0 talks .
- Listened to 0 podcasts episodes .
- Played 2 video games .
Books
How To English: 31 Days to be an independent learner
░░░▓▓▓▓░░░░░░░░
Los 88 Peldaños del Éxito
░░░░▓▓░░░░░░░░░
Recommended articles
10 Data-Driven Ways to Use Your Developer Resume to Get Interviews
Deprecating scp
Writing a Book with Pandoc, Make, and Vim
Eat the Frog
Quantify Yourself: (Mostly) Free Tools & Strategies to Track (Almost) Every Area of Your Life
- Read 3 books and 12 articles.
- Watched 2 movies , 8 TV episodes and 1 talks .
- Listened to 0 podcasts episodes .
- Played 3 video games .
Books
Docker Deep Dive
░░░░░░░░░░▓▓▓▓▓
- Read 3 books and 12 articles.
- Watched 2 movies , 8 TV episodes and 1 talks .
- Listened to 0 podcasts episodes .
- Played 3 video games .
Books
Docker Deep Dive
░░░░░░░░░░▓▓▓▓▓
How To English: 31 Days to be an independent learner
▓▓▓░░░░░░░░░░░░
Los 88 Peldaños del Éxito
▓▓▓▓░░░░░░░░░░░
Recommended articles
Want a More Productive Morning Routine? “Pay” Yourself First
Ten reasons to get about by bike
Don't Copy Paste Into A Shell
The story behind Markdown
It’s Going to Be a Long, Dark Covid Winter. Scandinavian Wisdom Can Help You Get Through It
Un salón, un bar y una clase: así contagia el coronavirus en el aire
Recommended Movies
Hogar
The Occupant is a Spanish thriller movie about a publicist who's unemployed and is forced to sell his apartment. Then he becomes obsessed with the new occupants and begins spying them with darkers intentions.
- Read 1 book and 8 articles.
- Watched 7 movies , 20 TV episodes and 1 talks .
- Listened to 0 podcasts episodes .
- Played 3 video games .
Books
Docker Deep Dive
░░░▓▓▓▓▓▓▓░░░░░
Recommended Articles
]]>- Read 1 book and 8 articles.
- Watched 7 movies , 20 TV episodes and 1 talks .
- Listened to 0 podcasts episodes .
- Played 3 video games .
Books
Docker Deep Dive
░░░▓▓▓▓▓▓▓░░░░░
Recommended Articles
7 software developer resume tips to help you stand out
Recommended Movies
The Social Dilemma
It's a dramatic documentary that analyzes the dangerous influence that social media have over us, with experts who talk about these dangerous tools they themselves have created.
Money Heist: The Phenomenon
A documentary about how "Money Heist" was involved in a wave of emotion and devotion around the world for a group of thieves and their professor. Recommended if you're a fan of this TV Show.
Recommended Games
Cuphead
If you're looking for a real challenge this is definitely your game. Cuphead is run and gun video game that was inspired by the style of animation used in cartoons of the 30s. The art style and animations are simply brilliant.

Here you have the quick recipe:
CREATE ROLE readonly;
GRANT CONNECT ON DATABASE mydatabase TO readonly;
\connect mydatabase
GRANT USAGE ON SCHEMA public to readonly;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO readonly;
CREATE USER myuser1 WITH PASSWORD 'secret_passwd';
GRANT readonly TO myuser1;
The deep dive(?)
Let's suppose you already have a well-securitized database with one or more users with the right privileges. If you still don't have your PostgreSQL database well protected, I recently wrote about how to securitize your database access well. You might find it useful.
Okay, so imagine someone asking you to create a read-only user to let an external provider connect and consume data, exporting reports, or whatever.
As we won't want to repeat all this process each time we need to create a read-only user, we'll create a role and then assign it.
So, for creating the read-only role, just type the following:
CREATE ROLE readonly;
We want this role to be able to connect to our database, so:
GRANT CONNECT ON DATABASE mydatabase TO readonly;
But, as you might know, this permission is not enough; we need to allow it to allow access to objects in the public schema.
\connect mydatabase
GRANT USAGE ON SCHEMA public to readonly;
As we may want to allow it to access all tables in the database, we'll type:
GRANT SELECT ON ALL TABLES IN SCHEMA public TO readonly;
But, If you only want to give access to specific tables, then type:
GRANT SELECT ON table_name TO readonly;
Now we have the role ready to use, so we're going to create a user and add it as a member.
CREATE USER myuser1 WITH PASSWORD 'secret_passwd';
GRANT readonly TO myuser1;
And that's it! Next time you need to create a read-only user it'll be a quick done task ;-)
If you have any question, doubt, or any improvement, feel free to let me know in this Twitter thread :)
If you found it useful, coffee is always appreciated. Thanks in advance!
More info at
]]>
The recipe:
CREATE USER myuser with password 'secret_passwd' role postgres;
CREATE DATABASE mydatabase with owner myuser;
\connect mydatabase
REVOKE ALL ON DATABASE mydatabase FROM public;
REVOKE ALL ON SCHEMA public FROM public;
ALTER SCHEMA public owner to myuser;
REVOKE myuser FROM postgres;
The deep dive
First things first
There are a few things you need to know to understand a bit about how PostgreSQL works.
-
CREATE USERandCREATE GROUPare aliases for theCREATE ROLEstatement. A user is just a role withLOGINprivileges.CREATE USER = CREATE ROLE + LOGIN privilege -
PostgreSQL has a
publicbackend role, and every new user and role inherits permissions from it. -
When a new database is created, PostgreSQL creates a schema called
publicand grants access on this schema to thepublicbackend role. Mmm... too many things called public here, don't you think? -
Because of this default behavior, any user can connect to new databases and create objects in each database's
publicschema.
Create the user
CREATE USER myuser with password 'secret_passwd' role postgres;
This statement will create a new user, and it'll add postgres role/user into myuser role. I know, syntax may look confusing.
Create the database
CREATE DATABASE mydatabase with owner myuser;
It creates a new database named mydatabase and makes myuser role the owner.
Securizes the database
\connect mydatabase
REVOKE ALL ON DATABASE mydatabase FROM public;
REVOKE ALL ON SCHEMA public FROM public;
Revokes all privileges on the new database and on the public schema to the public role. I mean, this revokes public access to the database.
Delegates ownership of public schema
ALTER SCHEMA public owner to myuser;
Now the user is the real owner.
The final part
Execute this query if you want to revoke access to this database even to postgres user. It's up to you.
REVOKE myuser FROM postgres;
Remember. After this, even though postgres user, which is the user with more RDS privileges, won't have access to that database. It'll only be accessible for myuser user.
In case you have to operate on it with postgres user, you'll need to grant access for it.
GRANT myuser TO postgres;
If not, you'll get a permission denied error.
If you have any question, doubt, or any improvement I could do, feel free to let me know in this Twitter thread :)
If you found it useful, coffee is always appreciated. Thanks in advance!More info at
Managing PostgreSQL users and roles
Managing PostgreSQL Database Access
PostgreSQL GRANT Documentation
PostgreSQL REVOKE Documentation
- Read 3 books and 6 articles.
- Watched 3 movies , 1 TV episodes and 1 talk .
- Listened to 0 podcasts episodes .
- Played 3 video games .
Books
Infrastructure as Code
▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓
- Read 3 books and 6 articles.
- Watched 3 movies , 1 TV episodes and 1 talk .
- Listened to 0 podcasts episodes .
- Played 3 video games .
Books
Infrastructure as Code
▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓
El libro que tu cerebro no quiere leer
▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓
Docker Deep Dive
▓▓▓░░░░░░░░░░░░
Articles
4 countries welcoming the digital nomads during Covid
How to stop procrastinating by using the Fogg Behavior Model
4 ways to make your to-do lists less overwhelming
Back To The Future: Unix Wildcards Gone Wild
Talk
]]>
Someone texted me with this tweet a few weeks ago. It made me remember how important the order of the parameters in some commands could be. Let's see the tweet.
I wanted to delete every file called "contents.html" so I ran:
— Tomas Sedovic (@TomasSedovic) February 9, 2020
find -type f -delete -name contents.html
It worked! But it also deleted every other file.
find's args are ordered. "delete" works on every match before it, ignoring anything after. "name" should have gone first.
As you may have noticed, some commands, such as find, take its parameters in order. So, this command:
find -type f -delete -name contents.html
is completely different from this another one:
find -type f -name contents.html -delete
The first one says find to look for every regular file and delete it. The second one says to look for every standard file that matches precisely with contents.html and then delete it.
As Tomas says in his tweet, the first one worked, but unfortunately, deleted all files, which could be a mess in a production system.
So, how to avoid this kind of situation?
First of all, mainly when I'm in a production system, I prefer to start typing a «#» as the first character. Why? Because I want to avoid executing an unfinished command by hitting the Enter key by mistake.
Instead of this, I always print the find's output first to ensure that it finds what we need.
find -type f -name contents.html -exec echo {} \;
This command will print the whole list of files which name matches precisely with «contents.html». Once we've ensured the output is ok, then we can delete them.
find -type f -name contents.html -exec rm -f {} \;
Another alternative to this command could be passing the output through a pipe, and then use xargs and rm.
find -type f -name contents.html | xargs rm -f
Now you don't have excuses! Don't forget, parameter order matters. When in production systems, I always try not to be creative.
So memorize the commands you usually use and write their parameters always the same order. Always. Being creative in production is not a good idea. Don't deal with the devil ;-)
]]>- Read 1 books and 13 articles.
- Watched 1 movies , 18 TV episodes and 2 talks .
- Listened to 0 podcasts episodes .
- Played 2 video games .
Books
When. The Scientific Secrets Of Perfect Timing
▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓
Games
]]>- Read 1 books and 13 articles.
- Watched 1 movies , 18 TV episodes and 2 talks .
- Listened to 0 podcasts episodes .
- Played 2 video games .
Books
When. The Scientific Secrets Of Perfect Timing
▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓
Games
Recommended articles
How to Start a Successful Negotiation in 2 Words
Write to a short attention span Brevity is the soul of wit
5 Words That Make Your Emails Sound Indecisive and Wishy-Washy
]]>
At the beginning of 2020, I released a list of my goals for the next 365 days. And now, here's a middle year review of the 17 goals I set for this year.
-
Improve my English skills.
On track: I started taking classes at a local English academy at the beginning of February. I also recovered my account at Babbel and started studying here too. At the end of April, I discovered 8Belts. So I started an eight-month course to improve my speaking fluency with them too. -
Travel more.
Failed: due to Covid-19, I'm not traveling this year. -
Read at least 1 book a month.
On track: I've already read 10 books this year. -
Swim more kms than 2019.
Failed: due to Covid-19, I stopped swimming. My last swim training was on the 9th of March, 2020. -
Get back to bodyweight workouts.
Behind target: due to Covid-19, I'm doing outdoor sports since I finished my personal lockdown. I'm trying to add this kind of workouts but I'm not being consistent weekly. -
Join some obstacle races.
Failed: due to Covid-19, all races were canceled. The one I joined was Spartan Virtual Race which was adapted to take part at home. -
Learn French. Look for some classes.
Failed: Postponed at least till next year. -
Have more fun time (playing videogames, etc).
On track: I'm playing one video game a month. -
Reduce procrastination.
On track: Working on it. I still procrastine but less than before. I'm tracking personal metrics to push myself do what I have to do. -
Improve wellbeing & mental health.
Behind target: I started doing meditation since March, but I reduced the number of sessions in June and July. I want to get back to it as a daily routine. -
Start doing yoga 2 or 3 times a week.
Behind target: I started practicing Yoga in March. I was motivated to do a Yoga session every day in the morning as part of my morning routine. But in June I decreased the number of sessions till zero in July. I want to recover it again as my morning or evening routine. -
Help people.
Behing target: I was thinking about doing volunteering. Instead of this, I donated money during the pandemic. -
TheRoot: make a website and publish there my photos.
Removed: I decided not put efforts on it. -
Get back to blogging in this blog.
Behind target: I migrated this blog from Hugo to Ghost again. And I'm starting blogging again, but not as much as I'd like.
- Read 1 books and 9 articles.
- Watched 1 movies , 15 TV episodes and 0 talks .
- Listened to 16 podcasts episodes .
- Played 2 video games .
Books
Do It Today
▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓
Recommended articles
]]>- Read 1 books and 9 articles.
- Watched 1 movies , 15 TV episodes and 0 talks .
- Listened to 16 podcasts episodes .
- Played 2 video games .
Books
Do It Today
▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓
Recommended articles
How I export, analyze, and resurface my Kindle highlights
How I use Shortcuts automations to make life run more smoothly
Why is there a "V" in SIGSEGV Segmentation Fault?
Your Emails Are 36 Percent More Likely to Get a Reply If You Close Them This Way
Recommended video games
]]>- Read 2 books and 7 articles.
- Watched 0 movies , 0 TV episodes and 6 talks .
- Listened to 0 podcasts episodes .
- Played 3 video games .
Books
Think Straight
▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓
Mi cuaderno estoico
▓░░░░░░░░░░░░░░
- Read 2 books and 7 articles.
- Watched 0 movies , 0 TV episodes and 6 talks .
- Listened to 0 podcasts episodes .
- Played 3 video games .
Books
Think Straight
▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓
Mi cuaderno estoico
▓░░░░░░░░░░░░░░
Recommended articles
Resolving the AddTrust External CA Root certificate expiration
Bare Metal in a Cloud Native World
Recommended Talk
]]>- Improve my English skills.
This is my number one goal for this year. I want to start taking English classes. - Travel more.
Make plans over calendar. Take WowTrips (or similar) into account for weekend trips. - Read at least 1 book a month.
- Swim more kms than 2019.
- Get back to
- Improve my English skills.
This is my number one goal for this year. I want to start taking English classes. - Travel more.
Make plans over calendar. Take WowTrips (or similar) into account for weekend trips. - Read at least 1 book a month.
- Swim more kms than 2019.
- Get back to bodyweight workouts.
- Join some obstacle races.
- Learn French. Look for some classes.
- Improve wellbeing & mental health.
- Have more fun time (playing videogames, etc).
- Reduce procrastination.
- Read more tech articles every week.
- Start doing meditation.
- Start doing yoga 2 or 3 times a week.
- Help people.
- TheRoot: make a website and publish there my photos.
- Get back to blogging in this blog.
Cuando aparece la necesidad de escalar una aplicación web, o cualquier otro servicio, en Internet; también aparecen nuevos problemas a resolver que antes incluso ni habíamos reparado en ellos. Uno de estos problemas es la compartición de ficheros entre servidores.
En mi opinión, a día de hoy éste sigue siendo
]]>
Cuando aparece la necesidad de escalar una aplicación web, o cualquier otro servicio, en Internet; también aparecen nuevos problemas a resolver que antes incluso ni habíamos reparado en ellos. Uno de estos problemas es la compartición de ficheros entre servidores.
En mi opinión, a día de hoy éste sigue siendo un dolor de cabeza para muchos Sysadmins o Systems Architects. Hay muchas formas de compartir ficheros entre servidores como NFS, S3FS, FileConveyor, un crontab con un rsync entre servidores. Hay muchas soluciones, algunas mejores y otras peores; pero hoy quería compartir la que hasta ahora creo que puede ser una buena solución para compartir ficheros, usando GlusterFS.
GlusterFS es un sistema de ficheros escalable en red, con el que poder crear soluciones de almacenamiento distribuidos por la red y de gran capacidad. Ni que decir tiene que GlusterFS es software libre.
Antes de empezar
Normalmente en los despliegues que hacemos en AWS en Crononauta, siempre utilizamos un mínimo de un par de instancias EC2 para el sistema de almacenamiento en red con GlusterFS. Además, a cada una de estas dos instancias EC2, hacemos attach de un disco EBS donde almacenaremos los ficheros en el clúster de ficheros en red. Esto nos permite tener redundancia en los datos, alta disponibilidad y escalabilidad horizontal en el servicio. Con lo cual, tendremos un par de instancias que mantienen en clúster de almacenamiento actuando como GlusterFS Server y por otro lado, tendremos los clientes de GlusterFS que montarán este volumen compartido por la red.
Como detalle, en Crononauta siempre usamos Debian como distribución, en este caso contamos con una Debian 8 (Jessie), aunque es totalmente aplicable a cualquier distribución basada en Debian como Ubuntu y/o derivadas.
Una vez tenemos esto, podemos empezar a trabajar... ;-)
Particionando los discos
Utilizaremos XFS como sistema de ficheros para el volumen compartido en red. Por lo que necesitaremos instalar las utilidades para trabajar con XFS, si no las tenemos ya instaladas.
apt-get install xfsprogs
El siguiente paso será crear una partición en el volumen, en mi caso es /dev/xvdf. Usaremos fdisk para ello:
fdisk /dev/xvdf
y una vez en la shell interactiva de fdisk, teclearemos:
npara crear una nueva partición. No necesitamos especificar nada más, así que los siguientes datos que pide podemos usar los valores por defecto que ofrecefdisk, asi que pulsaremosIntrohasta finalizar. Una vez hecho esto, seguiremos dentro de la shell interactiva defdisk, y habremos creado una partición primaria que ocupa todo el espacio del volumen.windicando que queremos escribir esta definición de partición en el disco y hacerla efectiva.
Ya tenemos la partición en el volumen, así que ahora la formatearemos y la añadiremos a nuestro /etc/fstab para montarla en cada arranque del sistema. Seguiremos los siguientes pasos:
mkfs.xfs -i size=512 /dev/xvdf1
mkdir -p /export/brick1
echo "/dev/xvdf1 /export/brick1 xfs defaults 1 2" >> /etc/fstab
mount -a && mount
Instalando GlusterFS
Ya tenemos el volumen preparado para GlusterFS, ahora instalaremos el servicio.
apt-get update
apt-get install glusterfs-server glusterfs-client glusterfs-common
Importante realizar este paso en aquellas instancias / servidores que vayan a actuar como un GlusterFS Server.
Lo siguiente que haremos será configurar nuestro fichero /etc/hosts para definir unos nombres DNS para nuestros GlusterFS Servers. También es posible hacerlo con un DNS interno. Si vuestros servidores, como en el caso de AWS EC2, contáis con IPs privadas, mejor usar esas. Si no, podéis usar las IPs pública.
Definiremos algo como lo siguiente en /etc/hosts:
xxx.xxx.xxx.xxx gfs01.example.com
xxx.xxx.xxx.xxx gfs02.example.com
Un anillo para gobernarlos a todos
Ya tenemos GlusterFS preparado para ser configurado. Ahora tendremos que configurar el anillo de confianza entre ambos servidores GlusterFS Server. Para ello serán necesarios los siguientes pasos:
-
Desde
gfs01.example.com:gluster peer probe gfs02.example.com -
Desde
gfs02.example.com:gluster peer probe gfs01.example.com
Es muy importante que haya conectividad entre ambos servidores, en caso contrario, los comandos anteriores fallarán. Si estás en AWS, asegúrate de tener bien configurado el Security Group para ambas instancias de storage.
Si todo ha ido bien, tendremos el pool de confianza funcionando, así que lo siguiente será definir el volumen compartido. Usaremos la siguiente instrucción desde uno de los servidores GlusterFS:
gluster volume create gv0 replica 2 gfs01.example.com:/export/brick1/<volume-name> gfs02.example.com:/export/brick1/<volumen-name»
Por último, iniciaremos el volumen que justo acabamos de crear:
gluster volume start gv0
Como detalle, podemos ver información sobre el volumen con la siguiente instrucción:
gluster volume info
Llegados a este punto, el cluster de almacenamiento debe estar totalmente operativo. Si queremos hacer una prueba, es posible crear el punto de montaje hacia el volumen compartido y probar si se replican correctamente los ficheros. Crearemos el punto de montaje en gfs01.example.com de la siguiente forma:
mount -t glusterfs localhost:/gv0 /mnt
Ahora crearemos ficheros para comprobar si el funcionamiento de GlusterFS es correcto. Con la siguiente instrucción crearemos diez ficheros vacíos en el punto de montaje previamente creado:
touch /mnt/test-file{1..10}.txt
Si GlusterFS funciona correctamente, debemos poder ver estos mismos ficheros en gfs02.example.com en el directorio /export/brick1/<volume-name>.
Configurando los clientes
Nos falta muy poco para terminar, ya sólo nos falta configurar los clientes de GlusterFS. Necesitaremos tener instalado el cliente de GlusterFS glusterfs-client si no lo tenemos instalado.
apt-get install glusterfs-client
Hecho esto, podremos probar a montar el volumen compartido por la red, y si todo va bien debemos ver los ficheros de prueba creados previamente.
mount -t glusterfs gfs01.example.com:/gv0 /mnt
Por último, necesitaremos un script /etc/init.d/glusterfs-mount que se encargue de montar el volumen compartido. En mi caso suelo utilizar el siguiente script:
#! /bin/bash
### BEGIN INIT INFO
# Provides: glusterfs-mount
# Required-Start: $remote_fs $syslog
# Required-Stop: $remote_fs $syslog
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Start daemon at boot time
# Description: Enable service provided by daemon.
### END INIT INFO
#
MOUNTPOINT="/var/www/shared"
GLUSTERFS_SERVER="gfs01.example.com"
GLUSTERFS_VOLUME="gv0"
# Some things that run always at boot
mount -t glusterfs $GLUSTERFS_SERVER:/$GLUSTERFS_VOLUME $MOUNTPOINT
#
# Uncomment this line if you need to start Apache after mount glusterFS volume
# service apache2 start
#
# Carry out specific functions when asked to by the system
case "$1" in
start)
echo "Mounting glusterfs volumes "
mount -t glusterfs $GLUSTERFS_SERVER:/$GLUSTERFS_VOLUME $MOUNTPOINT
;;
stop)
echo "Unmount glusterfs volumes"
umount $MOUNTPOINT
;;
*)
echo "Usage: /etc/init.d/glusterfs-mount {start|stop}"
exit 1
;;
esac
exit 0
Ya solo nos queda dar permisos de ejecución a nuestro script y configurarlo para que se ejecute durante el inicio del sistema:
chmod +x /etc/init.d/glusterfs-mount
update-rc.d glusterfs-mount defaults
FAQ
- Q: No puedo crear el anillo de confianza. Los comandos
gluster peer probeterminan fallando con un timeout ¿Qué ocurre?
- A: Es muy probable que sea un problema de conectividad entre ambos GlusterFS Servers. Revisa si hay algún firewall entre ellos que pueda estar bloqueando conexiones TCP y UDP
entre ellos. Puedes ver los puertos abiertos connetstat -ntlp.
Si estás en AWS, asegúrate que el Security Group que usan ambas instancias tienen permitidos los accesos a puerto TCP y UDP entre ellos.
- Q: No puedo montar el volumen compartido desde las instancias que actuan como clientes. El comando
mountresponde conmount failed. ¿Qué puede estar ocurriendo?
- A: Al igual que con los servidores GlusterFS, revisa que las instancias clientes tienen conectividad con los servidores. GlusterFS suele abrir un rango de puertos para cada volumen exportado (gv0, gv1, gv2, etc). Es recomendable permitir todo el tráfico TCP y UDP entre las instancias clientes y servidor. De otra forma es probable que alguna vez tengamos problemas al montar los volumenes.
- Q: Sigo sin poder crear el punto de montaje desde las instancias clientes. El comando
mountindica que hubo un problema. La conectividad entre cliente y servidor de GlusterFS es correcta ¿Qué problema puede haber?
- A: Es muy común que las versiones de las distribuciones entre cliente y servidor difieran. Si esto es así, es muy probable que la versión de
glusterfs-clientdifiera de la versión deglusterfs-server. En este caso, es muy probable que no podamos montar el volumen compartido con el driverglusterfs.
GlusterFS permite montar los volumenes con el driver de NFS. En este tipo de situaciones es normal recurrir al driver de NFS para crear el punto de montaje. Para ello se necesita tener instalado nfs-common y crear el punto de montaje con la siguiente instrucción:
mount -t nfs gfs01.example.com:/gv0 /var/www/shared
- Q: ¿Por qué crear un script en
/etc/init.dpudiendo configurar el montaje en el fichero/etc/fstab?
- A: Sí, es posible configurar el punto de montaje en
/etc/fstab, pero a diferencia del resto de punto de montajes, en este caso se trata de un volumen compartido por la red. Es muy probable que cuando se monten los volumenes de/etc/fstab, aún no esté disponible la red en el sistema, con lo cual el montaje no solo fallará, sino que además es posible que ralentize el arranque del sistema hasta que el intento de montar el volumen por la red de un Timeout. Por eso es más fiable hacerlo con un script eninit.d, una vez la red ya esté disponible.
Creo que esto es todo. ¿Encontráis algún otro problema? ¡Dejadlo en los comentarios!
Saludos.